 |
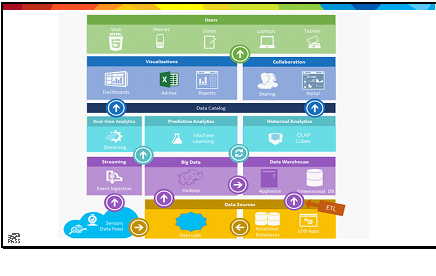
The goal of this presentation was to explore the Microsoft Data Platform from the perspective of a SQL Server professional; I found this great conceptual diagram of the platform from this website a while back, and wanted to use it as a framework. I figured the best way to teach a subject was the same way I teach my 3-year-old: a little bit of whimsy.
Enjoy. |
 |
You have brains in your head
And SQL Skills to boot
You’ll soar to great heights
On the Data Platform too
You’re on your own, and you know what you know,
And YOU are the one who’ll decide where to go.
You’ve mastered tables, columns and rows, OHHHHH MYYYY
|
 |
You may even have dabbled in a little B.I.
You’re a data professional, full of zest,
But now you’re wondering “What comes next?” |
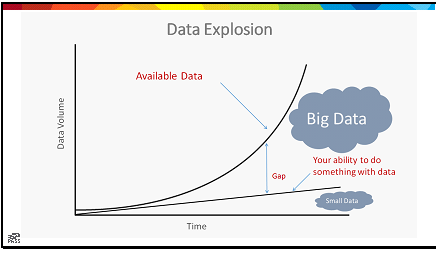 |
Data! It’s more than just SQL,
And there’s a slew of it coming, measured without equal.
Zettabytes, YotaBytes, XenoBytes and more
All coming our way, faster than ever before.
So what should we do? How should we act?
Should we rest on our laurels? Should we lie on our backs?
Do we sit idly by, while the going gets tough?
No… no, we step up our game and start learning new stuff!
|
 |
Oh, the places you’ll go!
ARCHITECTURE
Let’s start with the Theories,
The things you should know
Designing systems as services,
Are the route you might go.
Distributed, scalable
Compute on Demand
The Internet of Things
And all that it commands.
|
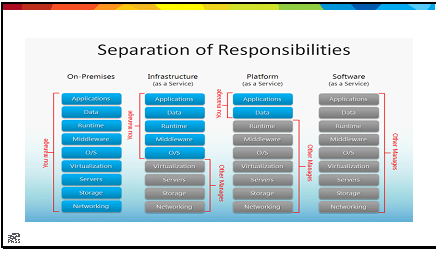 |
Infrastructure is base,
Platform is in line
Software and data
Rest on top of design
Once you’ve grasped this
Once you’ve settled in
You’ve embraced cloud thinking
Even while staying on-prem.
|
 |
But beyond the cloud, there’s data itself.
Structured, polyschematic, binary, and log
Centralized or on the edge,
Some might say “in the fog”
|
 |
Big Data, Fast Data, Dark, New and Lost
All of it needs management, all at some cost
There’s opportunity there to discover something new
But it will take somebody, somebody with skills like you.
Beyond relational, moving deep into insight
We must embrace new directions, and bring data to life
And there’s so many directions to go!
|
 |
ADMINISTRATORS
For those of you who prefer administration
System engineering and server calibration
You need to acknowledge, and you probably do
You’ll manage more systems, with resources few.
Automation and scripting are the tools of the trade
Learn powershell to step up your game.
Take what you know about managing SQL
And apply it to more tech; you’ll be without equal
|
 |
Besides the familiar, disk memory CPU
There’s virtualization and networking too
In the future you might even manage a zoo,
Clustering elephants, and a penguin or two.
|
 |
But it all hinges on answering things
Making servers reliable and performance tuning,
Monitoring, maintenance, backup strategies
All of these things you do with some ease.
And it doesn’t matter if the data is relational
Your strategies and skills will make you sensational
All it takes is some get up, and little bit of go
And you’re on your way, ready to know. |
 |
So start building a server, and try something new
SQL Server is free, Hadoop is too.
Tinker and learn in your spare time
Let your passions drive you and you’ll be just fine
DEVELOPERS
But maybe you’re a T-SQL kind of geek,
And it’s the languages of data that you want to speak
There’s lots of different directions for you
Too many to cover, but I’ll try a few
|
 |
You could talk like a pirate
And learn to speak R
Statistics, and Science!
I’m sure you’ll go far
Additional queries for XML and JSON
Built in SQL Server, the latest edition.
|
 |
You can learn HiveQL, if Big Data’s your thing
And interface with Tez, Spark, or just MapReducing
U_SQL is the language of the Azure Data Lake
A full-functioned dialect; what progress you could make!
There’s LINQ and C-Sharp, and so many more
Ways to write your code against the datastores
You could write streaming queries against Streaminsight
And answer questions against data in flight.
|
 |
And lest I overlook, or lest I forget,
There’s products and processes still to mention yet.
SSIS, SSAS, In-memory design
SSRS, DataZen, and Power BI
All of these things, all of these tools
Are waiting to be used, are waiting for you.
You just start down the path, a direction you know
And soon you’ll be learning, your brain all aglow |
 |
And, oh, the places you’ll go.
And once you get there, wherever you go.
Don’t forget to write, and let somebody know.
Blog, tweet, present what you’ve mastered
And help someone else get there a little faster.
|




 I’ve been rereading the book
I’ve been rereading the book