 As I’ve alluded to in earlier posts, my career goals have transitioned away from database development and administration into DevOps implementations; it’s been a bit of a challenge for me, because I feel like a stranger in a strange land all over again. Looking at familiar problems turned on their sides isn’t for me, and my day job has some particular challenges that I need to figure out appropriate solutions for. All of that being said, I’ve enjoyed it. However, in an attempt to help me wrap my head around things, I wanted to list out the struggles I’m facing, and include my current “solutions”; these may change over time, but it’s where I’m at today.
As I’ve alluded to in earlier posts, my career goals have transitioned away from database development and administration into DevOps implementations; it’s been a bit of a challenge for me, because I feel like a stranger in a strange land all over again. Looking at familiar problems turned on their sides isn’t for me, and my day job has some particular challenges that I need to figure out appropriate solutions for. All of that being said, I’ve enjoyed it. However, in an attempt to help me wrap my head around things, I wanted to list out the struggles I’m facing, and include my current “solutions”; these may change over time, but it’s where I’m at today.
-
It is what it is…
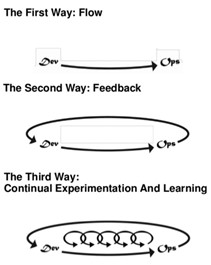
One of the challenges of describing DevOps is that it’s a conglomerate of technical and cultural changes. System and software engineers can easily understand the technical components of iterative software deployment, but it’s tough to describe the organizational and procedural changes necessary to implement a rapid deployment environment (“You want the developers on pager duty? How will they administer the system?”). Most engineers have a tough time interpreting The Phoenix Project, because it’s not a technical manual; they’re used to step-by-step guides, not cultural strategies.
My solution is to describe DevOps as a philosophy, not a methodology. Philosophies have general principles that you agree to abide by (such as seeking efficiency through automation, increasing feedback, and documenting problems without blame); methodologies are strategies for implementing philosophies. What this means is that as a manager, my method of implementing DevOps is probably different than yours, and there may even be differences within the organization; the key focus should be on reducing or eliminating silos through communication. Where those silos must remain (say, in a highly regulated environment where development and operations need to be separate), workflow in each silo needs to be as transparent as possible.
-
Brownfield change is harder than greenfield development.
Greenfield projects are new software projects or initiatives; brownfield development is a revitalization of an existing project. While each has challenges from a DevOps perspective, the technical and cultural debt that is associated with brownfield development often slows down adoption of DevOps practices. It’s tough to maintain a system while making suggestions for improvement, particularly when multiple departments are involved, all with their own goals.
For me, it all goes back to two principles: tight focus, and increased communication. As a change agent, I need to carve out time each week to focus on one small, incremental change that I can make to increase efficiencies; for example, I’m currently working on developing a standard postmortem practice for tracking issues with our business service (using this free guide from VictorOps). The point is that I may not have opportunity to make sweeping changes, but I can do a little bit at a time (and encourage my team to do so as well).
-
Compliance is a constraint.
Working in the financial industry brings some unique challenges to implementing DevOps; while philosophically the ideal DevOps process is to build automation pipelines from development through deployment, regulatory policies are written to dictate separation and control between environments. The thicker the wall, the more likely you are to successfully pass an audit, but those walls make it tough to attain rapid development. If your developers have one set of goals (deploy new features) and your operations team have another (keep the system stable with few changes), you’ve got to figure out a way to reconcile those.
Communication is key, and that includes have a common issue tracking system to report operational issues to development as soon as they occur; I don’t manage the developers in my business unit, so I can’t set their priorities. But I can make them aware of the pain points, and the expenses associated with those struggles. I can also find ways to make our infrastructure more predictable so that developers can develop code faster, and our QA teams can automate tests with some assurance. It’s tough, but it’s my goals.
Summary
I realize that this post may not be that insightful, but I’m looking at it as an effort to keep writing and thinking about these issues. Expect more from me in the future as I continue to try and learn something new.
 I know it’s clickbait, but I really did want to reinforce the simplicity of this post. I think building a DevOps culture can sometimes be daunting for most folks from traditional IT backgrounds because, well, people aren’t systems. You see, both developers and system engineers are comfortable with technology; it’s usually predictable, and it’s relatively easy to manipulate.
I know it’s clickbait, but I really did want to reinforce the simplicity of this post. I think building a DevOps culture can sometimes be daunting for most folks from traditional IT backgrounds because, well, people aren’t systems. You see, both developers and system engineers are comfortable with technology; it’s usually predictable, and it’s relatively easy to manipulate.