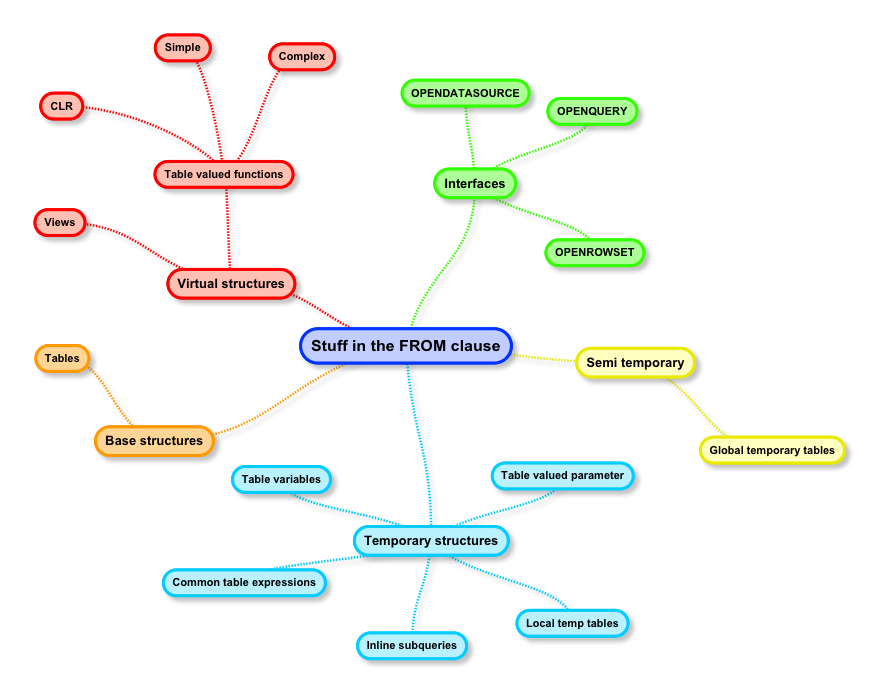
So way back in October, I started a blog series on Stuff in the FROM clause; I never finished it. I’m trying to return to writing, so I thought it would be best if I completed the remaining two posts (so I can tick one more item off my to-do list). If you really want to catch up, here’s the links to the first two posts:
Stuff in the FROM clause: Base Structures
Stuff in the FROM clause: Virtual Structures
Today’s post is touching on two different categories of database objects used in the FROM clause: temporary and semi-temporary structures. Temporary structures are database objects which are used within the context of a single scope or session in SQL Server; after their use, they are destroyed. Semi-temporary structures can be used across multiple scopes or sessions, but they are destroyed when the server is restarted.
TEMPORARY STRUCTURES
INLINE SUBQUERIES
An inline subquery is much like a view; it’s a method of encapsulating a SELECT statement inside another piece of SQL code for performance gains or simplification of the outer SQL statement. Inline subqueries exist only within the context of the outer SQL statement; they are not reusable from one statement to the next.
SELECT columnlist
FROM (SELECT columnlist
FROM table) a
Inline subqueries must have be referenced by an alias (in the above example, “a” is the alias). They can be used like any other object in the FROM clause.
COMMON TABLE EXPRESSIONS
A common table expression (CTE) is similar to an inline subquery; it’s a method of encapsulating a SELECT statement for reuse within another SQL statement; they are not reusable from one statement to the next.
; WITH a AS (SELECT columnlist FROM table)
SELECT columnlist
FROM a
CTE’s are very powerful piece of coding logic that deserves far more attention than this brief write-up; below are a couple of examples for additional reading (including how to do recursion in a CTE):
http://msdn.microsoft.com/en-us/library/ms186243.aspx
TABLE VARIABLES
Table Variables are another powerful temporary structure for managing data in SQL Server; a table variable is destroyed when it falls out of scope, which is more limited than the session of a temp table. Although there might be some slight performance gains associated with using small table variables (since they are created in memory first), the real benefit stems form their use as building blocks inside user-defined functions and table valued parameters (both to be introduced soon). The syntax for building a table variable is as follows:
DECLARE @t TABLE (ID int)
A note of caution: table variables are expected to be small (limited rows) by the SQL Server optimizer; execution plans may be negatively impacted if the amount of data being stored in a table variable is larger than x rows (and estimates for x varies greatly from 10 rows to 1000 rows). Note that table variables can only have one index; a clustered primary key that is created on request during the declaration.
TABLE-VALUED PARAMETERS
Table-valued parameters are related to table variables; they are primarily used to pass entire result sets from one stored procedure to the next. To be honest, I find the syntax a bit clunky, so I’m borrowing the sample code from Books Online to explain it:
USE AdventureWorks2008R2;
GO
/* Create a table type. */
CREATE TYPE LocationTableType AS TABLE
( LocationName VARCHAR(50)
, CostRate INT );
GO
/* Create a procedure to receive data for the table-valued parameter. */
CREATE PROCEDURE usp_InsertProductionLocation
@TVP LocationTableType READONLY
AS
SET NOCOUNT ON
INSERT INTO [AdventureWorks2008R2].[Production].[Location]
([Name]
,[CostRate]
,[Availability]
,[ModifiedDate])
SELECT *, 0, GETDATE()
FROM @TVP;
GO
/* Declare a variable that references the type. */
DECLARE @LocationTVP
AS LocationTableType;
/* Add data to the table variable. */
INSERT INTO @LocationTVP (LocationName, CostRate)
SELECT [Name], 0.00
FROM
[AdventureWorks2008R2].[Person].[StateProvince];
/* Pass the table variable data to a stored procedure. */
EXEC usp_InsertProductionLocation @LocationTVP;
GO
Basically, you declare a type to hold your result set, and then create a variable to reference that result set; since types are scope- and session-safe, you can then move data around as a variable (as opposed to using a global temporary table).
LOCAL TEMP TABLEs
Local Temp Tables are a temporary structure; they are stored in tempdb, and look and act very similarly to base tables. You can create indexes on them, you can ALTER their structure after creation, and you can use them exactly like a standard base table. The primary difference between a local temp table and a standard table is that the temp table is available only to the session in which it was created, and it’s destroyed after that session is over.
Syntactically, the CREATE statement for a local temp table is nearly identical to the CREATE statement for a base table; the only difference is that temp tables must have a single hash mark at the beginning of their name, i.e.:
CREATE TABLE #temp (ID int)
or
SELECT 1 as ID
INTO #temp
SEMI-TEMPORARY STRUCTURES
GLOBAL TEMP TABLEs
Global Temp Tables are a variation of the local temp table; the same basic rules apply, except that global temp tables are not automatically destroyed at the end of a session. Thus, they can be reused across multiple scopes and sessions just like a base table; however, if the server is restarted, the global temp tables are destroyed.
Syntactically, the CREATE statement for a local temp table is nearly identical to the CREATE statement for a base table; the only difference is that global temp tables must have two hash marks at the beginning of their name, i.e.:
CREATE TABLE ##temp (ID int)
or
SELECT 1 as ID
INTO ##temp
Alright; one more to go: Interfaces.