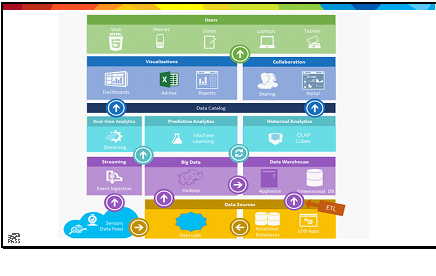
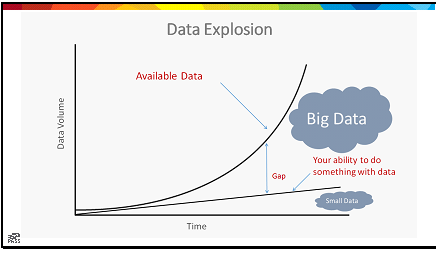
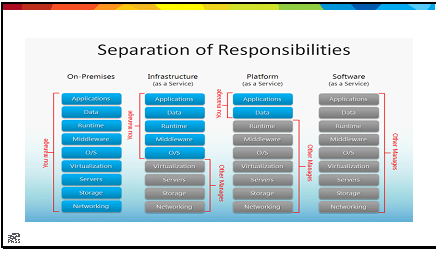
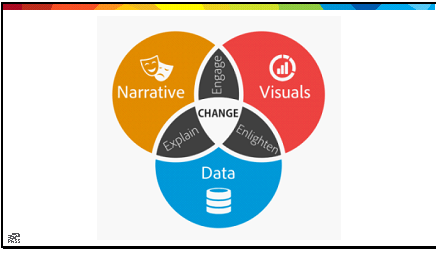
Last week, I had the pleasure of attending my first DevOps conference (DevOpsDays Nashville), and the first conference that had absolutely nothing to do with SQL Server since graduate school. The conference was great; I met some new folks, and had some great moments of insight early on. The DevOps community is a very welcoming community, but as a relatively new explorer, I quickly got lost. The sessions ranged from culture to technology, and somewhere in between; the speakers were very casual, and to be honest, a little unstructured. It was very different than my previous experiences at tech conferences, where even professional development talks were goal-focused.
Last week, I had the pleasure of attending my first DevOps conference (DevOpsDays Nashville), and the first conference that had absolutely nothing to do with SQL Server since graduate school. The conference was great; I met some new folks, and had some great moments of insight early on. The DevOps community is a very welcoming community, but as a relatively new explorer, I quickly got lost. The sessions ranged from culture to technology, and somewhere in between; the speakers were very casual, and to be honest, a little unstructured. It was very different than my previous experiences at tech conferences, where even professional development talks were goal-focused.
One the last day of the event, during one of the keynotes, I encountered the following tweet:
I’d love to hear people’s experience on this “DevOps is Disintegrating… But Maybe That’s OK” by @jpaulreed https://t.co/uc9mBJ97g7
— Kaimar Karu (@kaimarkaru) November 11, 2016
Paul Reed’s piece is interesting, because it helped me begin to form a schema around all that is DevOps; he defines the following frameworks underneath the umbrella of DevOps:
Automation and Application Lifecycle Management – basically, the tools needed to insure micro-deployments and increased time-to-market. The focus here is on Continuous IntegrationDeploymentDelivery, and Configuration Management.
Cultural Issues – Reed breaks these out into a relatively fine grain in a manner that he didn’t do with technology, but he defines three subsections of culture: Organizational Culture, Workflow, and Diversity. Each of these areas has a slightly different area of focus, but they all deal with the “soft, fuzzy, human interactions that lie just beyond the technology.” Organizational Culture can refer to breaking down silos, restructuring, and/or management & leadership. Workflow refers to the application lifecycle methodology, such as the conjunction of Agile and Lean methods. Diversity is a focus on bringing different voices into technology, including feminist, LGBTQ, and minority perspectives.
The Indescribable – finally, Reed finishes with basically an “everything else” definition. Some organizations which have pioneered DevOps practices don’t really call them that; they’ve just organically grown their own processes to focus on efficiency, including minimizing silos and rapid delivery.
I have to admit, it helped me to reframe my perspective on various lectures using this structure; that may not be true to the spirit of DevOps itself (which de-emphasizes artificial constraints), but it’s given me some room for thought in terms of the areas I want to study and learn. The technology is interesting, but I don’t see myself working in those areas anytime soon; my real focus will be on organizational culture and workflow. As a manager, I want to increase my efficiency by building a team, and I think the path I’m on is to figure out how to push my team of system engineers and database administrators to prepare for continuous integration.
More to come.