Been a while since I’ve posted, so I thought I’d try to put down some thoughts on a lightweight topic. I’m a full-time remote worker; I have been for the last 10 years). My company has embraced remote workers, and provides lots of tools for people to contribute from all over the country (including the wilds of North Georgia); tools include instant messaging clients, VOIP, remote presentation software, etc. Document sharing and discussion is easy, but as you probably know, DevOps is as much about relationship building as it is about knowledge sharing. How do you minimize silos between teams when teams aren’t physically located near each other?
Been a while since I’ve posted, so I thought I’d try to put down some thoughts on a lightweight topic. I’m a full-time remote worker; I have been for the last 10 years). My company has embraced remote workers, and provides lots of tools for people to contribute from all over the country (including the wilds of North Georgia); tools include instant messaging clients, VOIP, remote presentation software, etc. Document sharing and discussion is easy, but as you probably know, DevOps is as much about relationship building as it is about knowledge sharing. How do you minimize silos between teams when teams aren’t physically located near each other?
Here’s some different methods:
- 1. First, in-person communication provides the greatest avenue for relationship-building. Bringing a remote worker in from the field from time to time can greatly reduce isolation. If your chief developer is in Wisconsin, and your main sysops guy is in Georgia, flying both in periodically is probably the best way to create opportunities for conversation. Better yet, send them both to a conference somewhere in between.
- If in-person conversation is the gold standard for discussion but isn’t an option for economic or practical reasons, seek methods to emulate that experience. Conference calls or web conferencing tools are common, but video conferencing adds an additional dimension to discussions. In general, the higher the bandwidth, the better because it forces “presence” in conversations.
- Encourage remote employees to add depth to relationships by providing them with a virtual space to connect. Internal blogs (with personal pictures or activities), or slack channels for goofing off provide teams with meta information beyond their work ability. Knowing that another person loves Die Hard as much as you do gives you a common place to start building relationships.
- Organize virtual non-work events, such as multi-player gaming marathons (Leeroy Jenkins would be proud; NSFW) or virtual parties.
The main point is that while face-to-face interaction is desirable, it isn’t necessary. Employees (and companies) can thrive if they actively seek methods of encouraging high-bandwidth interactions with depth. Distance increases difficulty, but it’s not insurmountable.
Feel free to drop a suggestion for enhancing remote communication and decreasing silos.

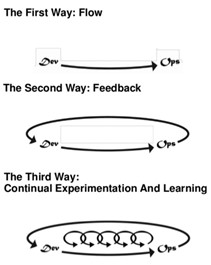 As I’ve alluded to in earlier
As I’ve alluded to in earlier  Last week, I had the pleasure of attending my first DevOps conference (
Last week, I had the pleasure of attending my first DevOps conference (