I’ve been presenting a lot on Big Data (specifically Hadoop) from the perspective of a SQL Server DBA, and I’ve made a couple of recent observations. I think most people are aware of the fact that data generation is growing at a staggering rate, with some estimates as high as 44 zettabytes by the year 2020; what I think is lacking in the SQL Server community is a rapid movement among database professionals to expand their skills to highly scalable Big Data platforms (like Hadoop) or streaming technologies. Don’t get me wrong; I think there’s people out there who have made the transition (like Michelle Ufford; SQLFool, now Hadoopsie), and are willing to share their knowledge, but by and large, I think most SQL Server professionals are accustomed to working with our precious relational system.
Why is that? I think it boils down to three reasons:
- The SQL Server platform is a complex product, with ever increasing opportunities to learn something new. SQL 2016 is about to drop, and it’s a BIG release; I expect most SQL Server people to wrap themselves up in new features and learn something new soon. There’s always going to be a need for deep expertise, and as the product continues to mature and grow, it requires deeper knowledge.
- Big Data tools are vast, untamed, and very organic. Those of us accustomed to the Microsoft development cycle are used to having a single official product drop every couple of years; Big Data tools (like Hadoop) are open-source, prone to various forks, and very rapidly developed. It’s like drinking from a firehose.
- It’s not quite clear how it all fits together. We know that Microsoft has presented some interesting data technologies as of late, but it’s not quite clear how the pieces all work together; should SQL Server pros learn Azure, HDInsight, Hadoop? What’s this about U-SQL? StreamInsight, Spark, Cortana Analytics?
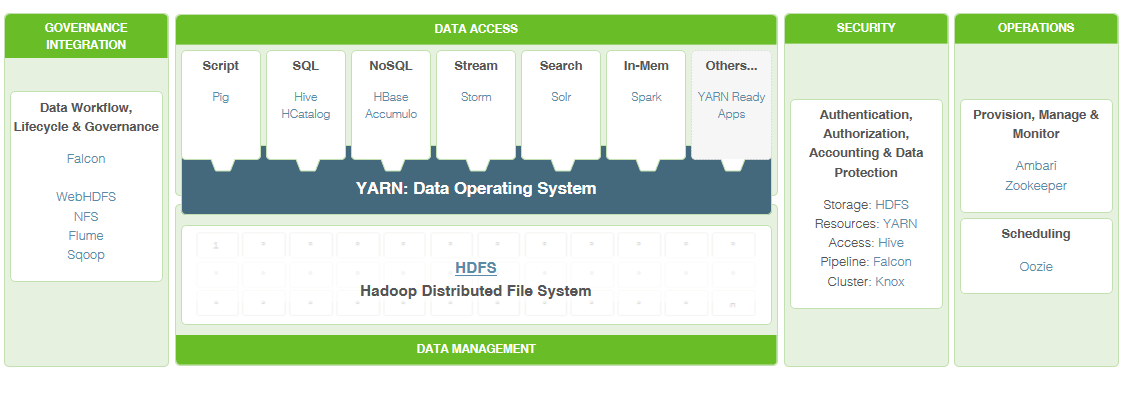
The first two reasons aren’t easily solved; they require a willingness to learn and a commitment to study (both of which are difficult resources to commit). The third issue, however, can be easily addressed by the following graphic.

This is Microsoft’s generic vision of a complete end-to-end analytics platform; for the data professional, it’s a roadmap of skills to learn. Note that relational engines (and their BI cousins) remain a part of the vision, but they’re only small pieces in an ever-increasing ecosystem of database tools.
So here’s the question for you; what should SQL Server people do about it? Do we continue to focus on a very specific tool set, or do we push ourselves (and each other) to learn more about the broader opportunities? Either choice is equally valid, but even if you choose to become an expert on a single platform in lieu of transitioning to something new, you should understand how other tools interact with the relational system.
What are you going to learn today?