There’s been some interesting conversation on the SQLSaturday slack channel regarding the admin tools for SQLSaturday. It was spawned, in part, by this great set of ideas proposed by the Godfather of SQL Saturday, Andy Warren, regarding changing the way that software development for the tools is handled by PASS HQ:
“So if that is all the way on one side of the scale (super closed system), the far other side is to open source it. Open source is also not simple. If you’re on the PASS Board you have to care about the potential loss of intellectual property. Scoff do you? No, there is no magic in the code, but it’s sweat equity and it’s a substantial part of what drives new members (and new email addresses for existing members) into the mailing list. Do you really want people forking it and spawning variations under different names?
Is there a middle ground? Sure. Let’s put together a straw man of what it might look like:
- PASS puts the source code into a private Github repo (because all devs love git!) along with a masked data set they can load/restore
- Write an agreement to get access to the source code and agree to not republish the code, plus convey to PASS the IP rights to new stuff
- Write the governance process. This is the hardest piece. Who will approve pull requests? Who decides which features get added? Who will do the testing? How often will releases be done (since PASS has to coordinate that)? Code standards. Rules about fonts and logos – all the stuff you deal with any dev shop.
- Down the road a little build a true dev environment where the latest code can be loaded and tested.”
It should be noted that Andy wrote (or oversaw) most of the original code for the SQLSaturday admin tools, so he’s no crackpot; he knows software development, he knows SQLSaturday, and he knows how to get things done. In fact, as I was writing this post, I went back and read some of my original posts about SQLSaturday #13 (back in 2009), I found myself reminiscing about all the advice he’s given to me (and countless others); when Andy proposes something, it’s usually a good idea to listen. And, when Andy says he wants feedback, he means it.
So here’s my feedback, based on the events I’ve helped run (I’ve lost count; it’s somewhere around 15); I question whether PASS needs to be in the admin tools game at all. 2018 is a very different landscape than 2007 (the very first SQL Saturday). Tools like EventBrite, Meetup, PaperCall.io, and Sched.com can provide a lot of the support required for the daily activities of running a SQLSaturday. Most are free for smaller events. All come without the cost of maintenance and support that are currently required to run the current admin site. By the way, I think the current tools are fine, but there do seem to be some ongoing reliability issues.
I brought this up on the Slack channel, and Steve Jones had some great counter arguments, including issues with integration and the recurring cost of these tools. I’m not sure that integration is an issue; I think that events have four different audiences, with four different needs:
- PASS needs members. They want email addresses from attendees to build their membership.
- Sponsors need leads; email addresses are great, but interested people are better (that’s usually achieved by the raffle system).
- Speakers need to manage submissions, and know where they’re supposed to be.
- Attendees need to register, order lunch, and see the schedule.
I’m not sure that having a single system to try and do everything is needed. I can envision PASS setting up a website and an email address, and then sponsors using a tool like Eventbrite to manage registrations. They can supply those email lists to PASS after the event to be imported into PASS’s databases. They can use a tool like Sched.com to manage speakers calls and build schedules. Eventbrite can be used to build the equivalent of Speedpass natively.
Thoughts?
 Very excited to be presenting an Ignite talk at #DevOpsDays #Nashville (October 17-18, 2017):
Very excited to be presenting an Ignite talk at #DevOpsDays #Nashville (October 17-18, 2017):  Been a while since I’ve posted, so I thought I’d try to put down some thoughts on a lightweight topic. I’m a full-time remote worker; I have been for the last 10 years). My company has embraced remote workers, and provides lots of tools for people to contribute from all over the country (including the wilds of North Georgia); tools include instant messaging clients, VOIP, remote presentation software, etc. Document sharing and discussion is easy, but as you probably know, DevOps is as much about relationship building as it is about knowledge sharing. How do you minimize silos between teams when teams aren’t physically located near each other?
Been a while since I’ve posted, so I thought I’d try to put down some thoughts on a lightweight topic. I’m a full-time remote worker; I have been for the last 10 years). My company has embraced remote workers, and provides lots of tools for people to contribute from all over the country (including the wilds of North Georgia); tools include instant messaging clients, VOIP, remote presentation software, etc. Document sharing and discussion is easy, but as you probably know, DevOps is as much about relationship building as it is about knowledge sharing. How do you minimize silos between teams when teams aren’t physically located near each other?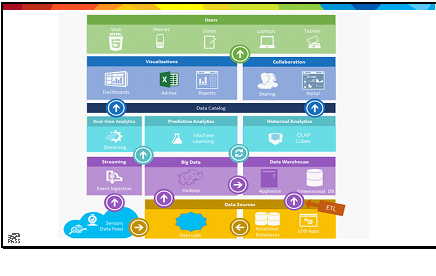


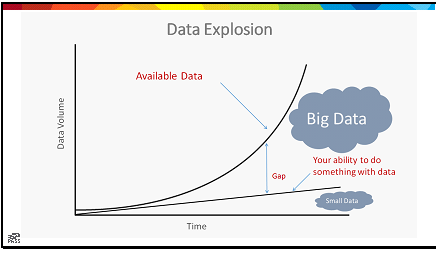

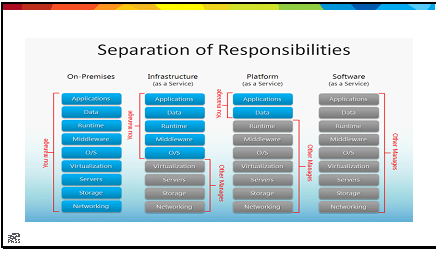

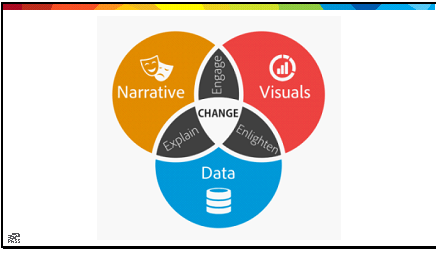








 I’ve been rereading the book
I’ve been rereading the book 
 Just a quick post as I’m packing up for the
Just a quick post as I’m packing up for the