Been reading some interesting arguments over the future of DBA jobs lately, and as usual, I find a lot of truth somewhere in the middle. Let me try to sum up the positions of the three authors that impressed me the most:
|
|
|
|
|
|


Thomas LaRock – Why I’m Learning Data Science:
Tom kind of kicked off this discussion with his post; the three main takeaways I got from it are:
- The traditional role of the DBA is being automated away, right in front of our keyboards.
- As computers get better about self-tuning, it will be difficult to justify the expenditure of a dedicated database administrator
- Computers are only good at providing answers; humans are good at asking questions.
Brent responded via twitter to “a couple of emails” stating that “the DBA career has a time bomb”. The three key points I got out of the thread are:
- The tools are getting better, but the problems are getting harder.
- SQL Server still ships with some legacy baggage that require hands-on experience to adjust; if computers were smart, why hasn’t that been fixed?
- Even as the technology gets better, adoption is slow.
Grant Fritchey – There Is A Magic Button, A Rant
Grant took the humorous route, telling the tale of the “Run Really Fast” button that all database administrators know about once they achieve a certain level of competence.
- Tools are getting better, but they can’t fix problems with design (both software and hardware).
- Automation can reduce drudgery, but design is fundamental.
- DBA’s are all secret alchemists.
Where I sit…
All three of these guys are smart folks that I respect a lot, and honestly, I see a lot of truth in what they’re all saying. The tools ARE getting better, and I do believe that automation is going to significantly change a lot of different jobs in IT, including database administrators. The role of a DBA is particularly susceptible to this because of the hybrid nature of the work. There’s elements of design (system and software), development, and operations associated with that role, and the stack is getting increasingly complicated. The Microsoft Data Platform now sits over relational and non-relation data, and encompasses analytics, visualization, reporting, integration services, high availability, disaster recovery, and much more. The stack is getting too complicated for the average DBA to be a master of all of it. However, it’s hard to deny the necessity of expertise, particularly with all of the technical debt associated with a product like SQL Server.
But what if we sliced the stack differently?
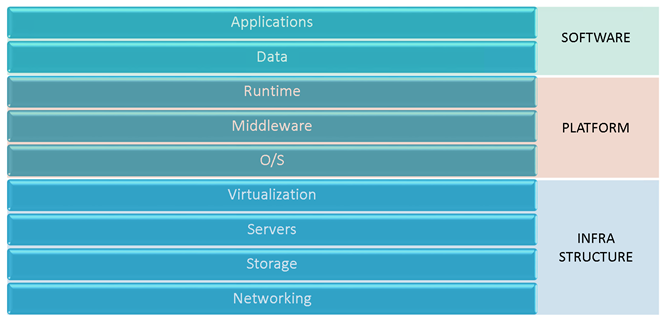 The cloud paradigm talks about breaking the computing stack up into various services, each acting as a black box to the level above it; Software as a Service is built on top of a Platform as a Service, which in turn is built on top of an Infrastructure as a Service. As enterprises begin to embrace the cloud, they will reorganize resources along these lines. Why? Because it lays the foundation for consolidating resources where it counts, and allows for future portability. In other words, companies can start at the bottom of the stack, and port their Platform and Software services over to cloud providers without significant alteration of those upper level. Likewise, as technology matures, migrating the Software layer to a new Platform provider will get easier over time (we’re not there yet, but it’s coming).
The cloud paradigm talks about breaking the computing stack up into various services, each acting as a black box to the level above it; Software as a Service is built on top of a Platform as a Service, which in turn is built on top of an Infrastructure as a Service. As enterprises begin to embrace the cloud, they will reorganize resources along these lines. Why? Because it lays the foundation for consolidating resources where it counts, and allows for future portability. In other words, companies can start at the bottom of the stack, and port their Platform and Software services over to cloud providers without significant alteration of those upper level. Likewise, as technology matures, migrating the Software layer to a new Platform provider will get easier over time (we’re not there yet, but it’s coming).
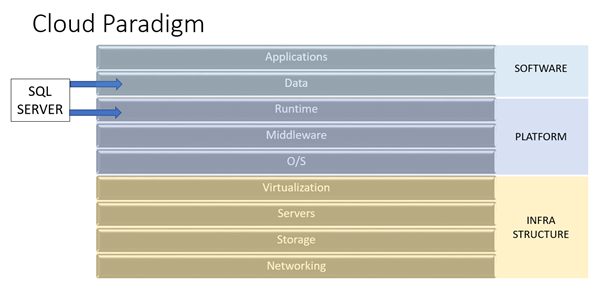
I would argue that the current role of database administration straddles the line between software and platform; traditional maintenance and server configuration task are part of the Platform layer, and database design are part of the Software layer. The term DBA will mean multiple things to multiple people, depending on where that role sits along this divide. In other words, a DBA that works at the Software layer will tend to focus on questions of database design, data software performance tuning, and architectural issues associated with the ever expanding set of options for databases beyond just the relational db. DBA’s at this layer need to become full-fledged member of the development team, which may eventually lead to a fuzzier distinction between application and database developers. DBA’s at this layer will need to be well-versed in the concepts of multiple data management technologies (and possibly other development technologies). Opportunities should abound here, but diversity should be valued over full-stack mastery of a single product.
DBA’s at the Platform level will change roles as well; they’ll no longer need to be steward of data, or responsible for tuning bad code. Their job will be to make the Platform support contracted levels of performance, and identify and correct resource utilization and configuration issues. Automation will have a huge impact here; Platform DBA’s will be responsible for supporting multiple instances of SQL Server, including support for high availability and disaster recovery. Scripting skills are highly desirable, as is mastery knowledge of specific products. I would expect job opportunities to slow in this area, but experts will still be needed in the future.
In short, I don’t think the role of a DBA is going away, but I do think that it’s going to split. That’s exciting, because it means that people have options. We still need experts, and there will still be opportunities for folks who love data to find meaningful work; their expertise will just become part of a different structure than we’re accustomed to now.
Now, where’d I put that Philosopher’s Stone?







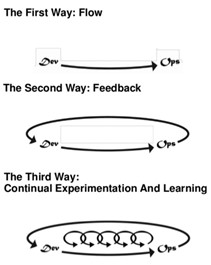
 There’s been some great discussion in the
There’s been some great discussion in the  I used to present a session called
I used to present a session called  Been a while since I’ve posted, so I thought I’d try to put down some thoughts on a lightweight topic. I’m a full-time remote worker; I have been for the last 10 years). My company has embraced remote workers, and provides lots of tools for people to contribute from all over the country (including the wilds of North Georgia); tools include instant messaging clients, VOIP, remote presentation software, etc. Document sharing and discussion is easy, but as you probably know, DevOps is as much about relationship building as it is about knowledge sharing. How do you minimize silos between teams when teams aren’t physically located near each other?
Been a while since I’ve posted, so I thought I’d try to put down some thoughts on a lightweight topic. I’m a full-time remote worker; I have been for the last 10 years). My company has embraced remote workers, and provides lots of tools for people to contribute from all over the country (including the wilds of North Georgia); tools include instant messaging clients, VOIP, remote presentation software, etc. Document sharing and discussion is easy, but as you probably know, DevOps is as much about relationship building as it is about knowledge sharing. How do you minimize silos between teams when teams aren’t physically located near each other?





 As I’ve alluded to in earlier
As I’ve alluded to in earlier {kind=link}