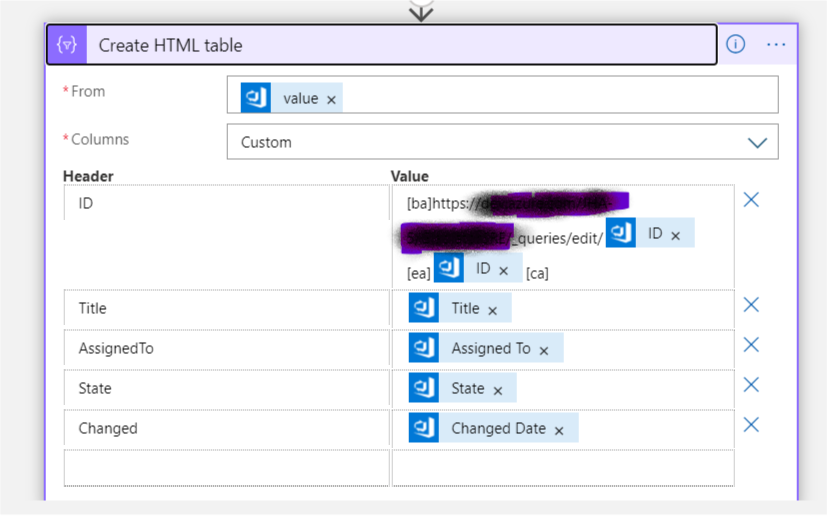
A big part of my job these days is looking for opportunities to improve workflow. Automation of software is great, but identifying areas to speed up human processes can be incredibly beneficial to value delivery to customers. Here’s the situation I recently figured out how to do:
- My SRE team uses a different Azure DevOps project than our development team. This protects the “separation of duties” concept that auditors love, while still letting us transfer items back and forth.
- The two projects are in the same organization.
- The two projects use different templates, with different required fields.
- Our workflow process requires two phases of triage for bugs in the wild: a technical phase (provided by my team), and a business prioritization (provided by our Business Analyst).
- Moving a card between projects is simple, but there were several manual changes that had to be made:
- Assigning to a Business Analyst (BA)
- Changing the status to Proposed from Active
- Changing the Iteration and Area
- Moving the card.
To automate this, I decided to use Azure Logic Apps. There are probably other ways to approach this problem (like Powershell), but one of the benefits of the Logic Apps model is that it uses the same security settings as our Azure DevOps installation. It just simplifies some of the steps I must go through. The simplest solution I could implement was to move the work item when changing the Assigned To field to a Business Analyst. This allows us to work the card, add comments, notes, but when the time comes to hand over to our development team for prioritization, it’s a simple change to a key attribute and save.
Here’s the Logic Apps workflow overview:
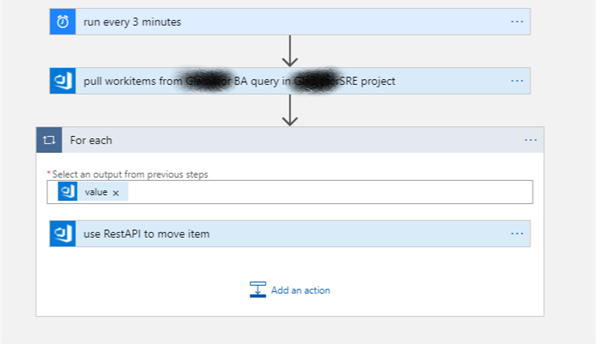
The initial trigger is a timer; every 3 minutes, the app runs and looks for work items that exist in a custom AzureDevOps query. This functionality is built into the Logic Apps designer as an Action for the Azure DevOps connector. The query exists in our SRE project, and simply identifies WorkItems that have been assigned to our Business Analyst Group. Note that the BA group is a team in the SRE project.
SELECT
[System.Id]
FROM workitems
WHERE
[System.TeamProject] = @project
AND [System.WorkItemType] <> ''
AND [System.State] <> ''
AND [System.AssignedTo] IN GROUP '[SRE]\BA <id:56e7c8c7-b8ef-4db9-ad9c-055227a30a26>'
Once this query returns a list of work items to the LogicApp, I then use a For Each step in the designer, and embed a Rest API action.
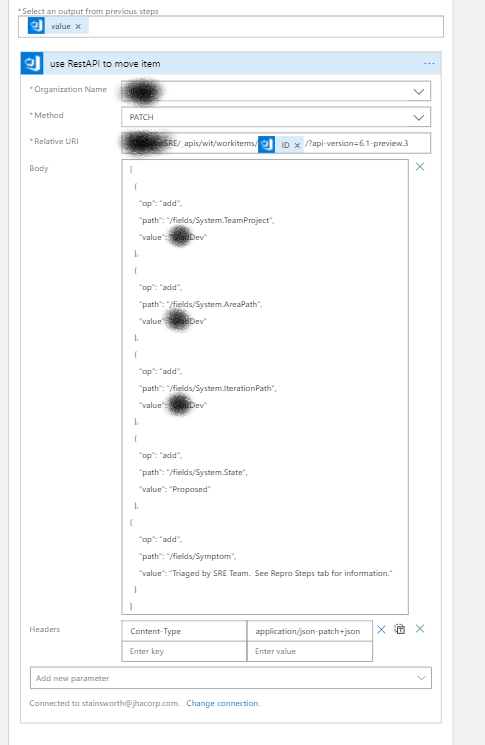
The Rest API action offers maximum flexibility to update values for a work item; there is also an Update action, but the options were limited. There was once gotcha; you have to add the content-type, or it throws an error: application/json-patch+json
The code is below; it’s JSON, and the syntax is that you specify an operation (“add” for both updates and creates), a path to the field you want to change (path), and the value you want to set it to. In this case, I’m changing the Project, The Area Path, the Iteration Path, the State of the Work Item, and adding a comment to the Symptom field.
[
{
"op": "add",
"path": "/fields/System.TeamProject",
"value": "Dev"
},
{
"op": "add",
"path": "/fields/System.AreaPath",
"value": "Dev"
},
{
"op": "add",
"path": "/fields/System.IterationPath",
"value": "Dev"
},
{
"op": "add",
"path": "/fields/System.State",
"value": "Proposed"
},
{
"op": "add",
"path": "/fields/Symptom",
"value": "Triaged by SRE Team. See Repro Steps tab for information."
}
]