If you’re at all in touch with the DevOps community, you’re probably aware of the GitLabs Incident on 1/31/2017; I won’t spend too much time rehashing it here, but GitLabs has done a great job of being transparent about the issue and their processes to recover. Mike Walsh (Straight Path Solutions) wrote a great blog post about it entitled DevOps: Don’t Forget The Ops, which covers a lot of ground from a database administration perspective. Mike ultimately ends up with three specific action items for DevOps teams:
- Plan to Fail (so you don’t)
- Verify Backups (focus on restores, not backups)
- Secure your environment (from yourself).
I agree with all of these ideas; I think Mike is spot on about the need to Remember the Ops in DevOps. However, I want to go a step further, and encourage DevOps adoptees to Embrace the Ops.
What do I mean by that? Let me start with this; Brent Ozar posted this on Facebook yesterday (the image will take you to the job description):

Now, it’s obvious that GitLabs had a backup strategy (they detailed it in their notes), so I don’t mean to imply that they didn’t expect administrative tasks from their database people, but I do think we can infer that administrative tasks were not prioritized as much as other tasks (high availability, performance tuning, etc.). Again, we know that GitLabs had strategy for backups, so it appears that this is a cultural issue (at least based on this flimsy evidence and the outage). And to some degree, that’s understandable; one of the longest running challenges on the operations side is being labeled as a cost center as opposed to development being viewed as a revenue generator. This perception is pervasive in traditional IT shops, so it’s probable that even Unicorn shops share some of this mentality. Development (new features) makes money; Operations cost money.
However, in a true DevOps model, the focus is on delivering quality services to customer, faster. New features may bring new clients, but reliable service retains clients; both are revenue generating. So while it may add some cost to deliver quality service to customers, cutting corners in operations risks impacting the bottom line. From this perspective, I’m arguing that DevOps shops should not only remember the ops, they should embrace it. The entire value stream of a business service includes people, procedures, and technology split into teams; the fewer the teams per service, the fewer silos. So how do we embrace the ops?
- If Ops is part of the Value Stream, then apply consistent Development principles to it. I’ve written before that “we are all developers“, and I believe that; administrators are creative folk, just like application developers. Operations includes backup, monitoring, and validation. We should apply development principles to these operations, like creating reusable scripts, finding opportunities for automating validation, and logging (and investigating) errors with that pipeline. We should use source control for these tools, and treat the operations pipeline like any other continuous integration project (automate your backup, automate your restores, and log inconsistencies).
- Include operational improvements as part of the development pipeline. I’m borrowing a lot from Google’s SRE model; SRE is what you get when you treat operations as if it’s a software problem (see point 1 above). However, the SRE model is usually a self-contained bubble within operations; they have their own pipelines for toil reduction. I think if DevOps wants to truly embrace operations, developers need to include toil reduction in the service delivery pipeline. If operations folks have to flip 30 switches to bring an app online, development should make it a priority to reduce that (if possible). It goes back to the fundamental rule for DevOps: communicate. Help each other resolve pain points, and commit to improving everything in the value stream.
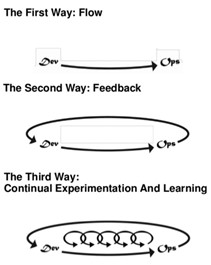
- Finally, balance risk and experimentation with safety. Gene Kim’s The Phoenix Project provides the Three Ways, and the Third Way is all about creating a culture that rewards risk and experimentation. This is great for developers; try something new, and if it breaks, you can deliver a fix within hours. However, as the GitLabs incident shows, some fixes can’t be delivered, and risk needs to be mitigated by secure data handling processes and procedures. While I’m a big fan of controlled failures (e.g., shutting a server down hard in order to see what the impact is), you don’t do that unless you can test it in a lab first and make sure you have good mitigating option (how do you recover? What error messages do you expect to see? Are you sure your backup systems are working?). Don’t forsake basic safety nets while promoting risk; you want competitive advantages, but you also want to stay in business.





 As I’ve alluded to in earlier
As I’ve alluded to in earlier  Last week, I had the pleasure of attending my first DevOps conference (
Last week, I had the pleasure of attending my first DevOps conference (

 I’ve been rereading the book
I’ve been rereading the book  Continuing in my efforts to chronicle myths of kanban utilization, I thought I would tackle the second biggest misconception I see surrounding kanban boards. As I discussed in my
Continuing in my efforts to chronicle myths of kanban utilization, I thought I would tackle the second biggest misconception I see surrounding kanban boards. As I discussed in my 
 Recently, my friend
Recently, my friend