I’ve been intrigued by the whole concept of Big Data lately, and have started actually presenting a couple of different sessions on it (one of which was accepted for PASS Summit 2014). Seems only right that I should actually *gasp* blog about some of the concepts in order to firm up some of my explanations. Getting started with Hadoop can be quite daunting, especially if you’re used to relational databases (especially the commercial ones); I hope that this series of posts can help clear up some of the mystery for the administrative side of the house. Before we dive in, I think it’s only fair to lay out some of the initial challenges with discussing Big Data in general, and Hadoop specifically. Depending on your background, some of these may be more challenging than others.
Rapid Evolution
Welcome to the wild, wild west. If you come from a commercial database background (like SQL Server), you’re probably accustomed to a mature product. For Microsoft SQL Server, a new version gets released on what appears to be a 2-4 year schedule (SQL 2005 -> 2008 -> 2012 -> 2014); of course, there’s always the debate as to what constitutes a major release (2008 R2?), but in general, the core product gets shipped with new functionality, and there’s some time before additional new functionality is released.
Hadoop’s approach to the release cycle is much looser; in 2014 alone, there have been two “major” releases with new features and functionality included. Development for the Hadoop engine is distributed, so the release and packaging of new functions may vary within the ecosystem (more on that in a bit). For developers, this is exciting; for admins, this is scary. Depending on how acceptable change is within your operational department, the concept of rolling out an upgraded database engine every 3-4 months may be daunting.
Ecosystems, not products
Hadoop is an open-source product, so if you’re experienced with other open-source products like Linux, you probably already understand what that means; open-source licensing means that vendors can package the core product into their product, as long as they allow open access to the final package. This usually means that commercial providers will either bundle an open-source product with their own proprietary side-by-side software (“we interface with MySQL” or “we run on Linux”), or they release their modified version of the software in a completely open fashion and earn revenue from a support contract (e.g., Red Hat). In either case, it’s an ecosystem, not a canned product.
Hadoop technically consists of four modules:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
However, take a look at the following framework from Hortonworks (the Microsoft partner for Hadoop):
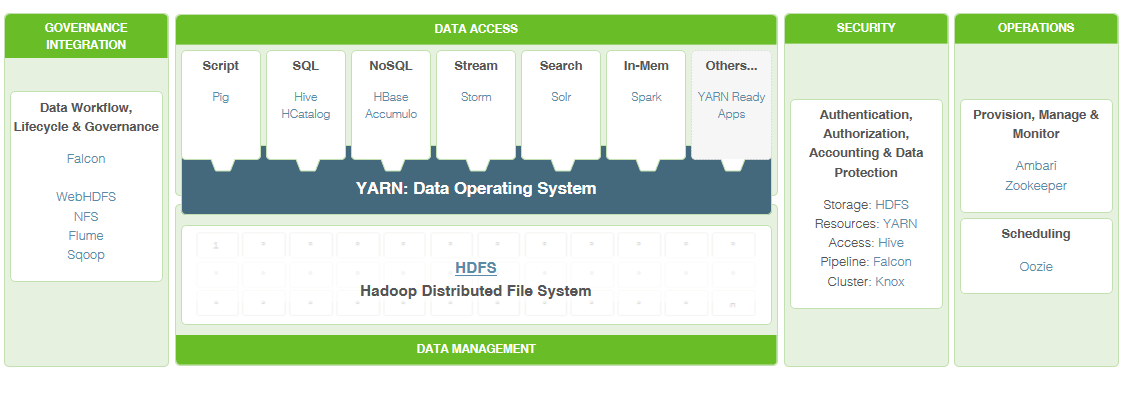 Lots of stuff in there that’s being developed, but isn’t officially Hadoop. it could become part of this official stack at some point, or it may not. Other vendors may adopt it, or they may not. Each of these components has their own update schedule (again, change!), but there is some flexibility in this approach (you can upgrade only the individual components); it does make the road map complex compared to traditional database platforms.
Lots of stuff in there that’s being developed, but isn’t officially Hadoop. it could become part of this official stack at some point, or it may not. Other vendors may adopt it, or they may not. Each of these components has their own update schedule (again, change!), but there is some flexibility in this approach (you can upgrade only the individual components); it does make the road map complex compared to traditional database platforms.
Big Data doesn’t always mean Big Data.
Perhaps the hardest thing to embrace about Big Data in general (not just Hadoop) is that the nomenclature doesn’t necessarily line up with the driving factors; a Big Data approach may be the best approach for smaller data sets as well. In essence, data can be described in terms of the 4 V’s:
- Volume – The amount of data held
- Velocity – The speed at which the data should be processed
- Variety – The variable sources, processing mechanisms and destinations required
- Value – The amount of data that is viewed as not redundant, unique, and actionable
A distributed approach (like Hadoop) is usually appropriate when tackling more than 1 of these four v’s; if your data’s just large, but low velocity, variety, or value, a single installation of SQL Server (with a lot of disk space) may be appropriate. However, if your data has a lot of variety and a lot of velocity even if it’s small, a Big Data approach may yield considerable efficiency. The point is that big data alone is not necessarily the impetus for using Hadoop at all.
Summary
Big Data & Hadoop are complex topics, and they’re difficult to understand if you approach them from a traditional RDBMS mentality. However, understanding the fundamentals of how Big Data approaches are evolving, disparate, and generally applicable to more than just volume can lay a foundation for tackling the platforms.

